Optimize LLM Enterprise Applications through Embeddings and Chunking Strategy.
Written by Aravind Kondamudi and Purnesh Gali.
As a follow-up to our previous post on Generative AI 101, we wanted to delve into something a bit more fundamental before discussing fine-tuning: our experience with embeddings and chunk size.
If you’re already comfortable with the basics, feel free to skip ahead to our section on “chunk sizes” to learn about the tests we did.
Embeddings are essential for building large language model (LLM) applications. They enable transforming text data into useful insights, powering intelligent chatbots, improving Q&A systems, and creating intuitive search engines. The magic behind many enterprise LLM applications lies in how they leverage embeddings to understand language.
What are embeddings?
In simple terms, embeddings convert text data into a format that machine learning algorithms can readily understand. And, word embeddings create dimensions (features) for every word. For instance, if you have the word ‘cat’, the dimensions might include ‘animal’, ‘pet’, ‘domestic’, ‘mammal’, ‘fur’, and so on. This is crucial when you want to find words that are similar to each other.
There are plenty of resources available if you want to understand this better.
How to create embeddings, and what to look for in an embedding model?
There are various models available that can generate embeddings for you, and each model is distinct. An embedding model is also a machine learning model that has been trained on a vast amount of data. You can find the top embedding models here.

You might notice in the leaderboard that the top models create 1024 or fewer dimensions, while OpenAI’s text-embedding-ada-002, even though it creates 1536 features, is only tenth on the list. This tells us that an embedding model creating more dimensions isn’t always better.
an embedding model creating more dimensions isn’t always better
But how do you pick the right embedding model? Unfortunately, we don’t have a clear answer for that. Because these models are a bit of a black box, you won’t really know if one works for you until you try it out. But based on our own experience, many of the top models worked pretty well for our needs. We found that the size of the chunks mattered more than the model itself. So, you may start with a model that you can easily access and that won’t break the bank.
What is chunking?
All embedding models have a limit to how many words they can handle at once, a ‘token’ limit. For text-embedding-ada-002, the limit is currently 8096 tokens, about 10 pages worth of words (this blog is ~1800 tokens). It’s not nearly enough for any use case that needs to process hundreds of pages at a time. Because there’s a limit to how many tokens a model can handle at once, you’ll need to split your data up into chunks that fit within the model’s limit. If you have 100 pages of data, for example, you’d make 10 chunks for the model to create 10 embeddings from.
When a user poses a question, your model identifies the most similar chunk and provides a summary as the answer. However, if you were to simply split your data into chunks every 10 pages, you might end up creating a chunk in the middle of a relevant piece of information, thus losing some context. When you search for something, the model might give you the first chunk that’s similar, but any related information present in the next chunk might not be returned, resulting in incomplete information.
Because there’s a limit to how many tokens a model can handle at once, you’ll need to split your data
To avoid this, you could use strategies like having some overlap between your chunks, adding extra context to each chunk, or summarizing each chunk and passing that summary on to the next one.
Here are some strategies we experimented with:
- Overlap of text between chunks, meaning that the last few sentences are repeated in the next chunk. However, you’ll need to experiment to determine the necessary percentage of overlap.
- Adding extra context to every chunk in the form of metadata.
- Summarizing each chunk and passing that summary on to the next one.
Is a large chunk size better?
Understanding why and how to chunk data for embeddings naturally leads to the question of chunk size. Is a larger chunk size always better? Should you max out at 8k tokens with text-embedding-ada-002? The simple answer is no, but there is no formula to arrive at this.
As models evolve, their token-processing capacity increases. There are experiments showing that large chunks can result in poor outcomes. Therefore, understanding the role of chunk size is crucial.
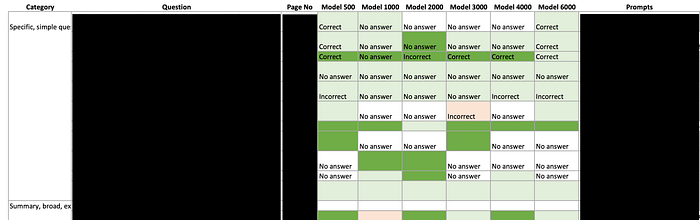
The experiments we conducted to determine the chunk size
We compiled a list of our business questions, ranging from simple to broad and highly exploratory, created different embedding sizes, and meticulously recorded the results for each size. We conduct other experiments like different prompts, cosine similarity, etc., so we use Streamlit to seamlessly test this. We are sharing a view of one such experiment.
We recognize that there’s a limit to the number of experiments one can conduct, so we consider this data as one of many factors before choosing which model to deploy in a production environment.
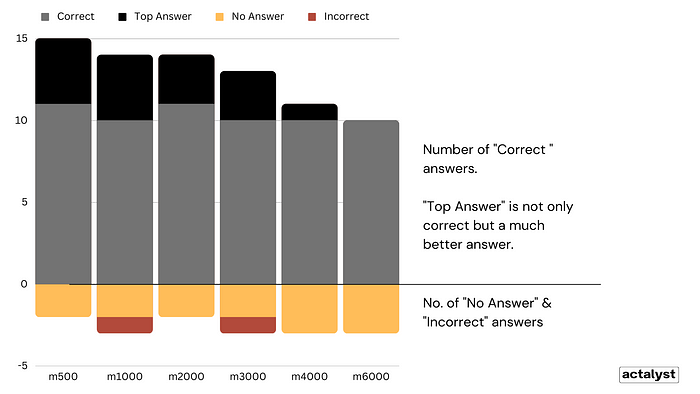
It should come as no surprise that none of the models in the given examples are perfect. Imperfections are found across the board, and the task is to choose what’s least flawed, or more appropriately, what’s best suited for your use cases.
A chunk size of less than 2,000 looks ideal in the above experiments, though there are some incorrect answers. However, we would be the first not to generalize this too broadly.
As a side note, we observed that the prompt itself didn’t significantly affect the quality of the answer in this specific case. We experimented with prompts that are simple and ones that are much more comprehensive and quite different. Yet, the results from all prompts were acceptable.
Advanced chunking strategies
If no single model is yielding the results you need, why stick to just one size? Could we use different sizes for different use cases? Or even better: develop a classifier to understand the type of question and direct it to the appropriate embedding size.
One size doesn’t fit all.
It’s certainly possible, but this introduces many more variables to manage and accurately track results before deploying in a production environment. To keep this blog short, we won’t delve into this topic here, but feel free to reach out to us if you’d like to discuss it further.
In essence, here’s what we’ve learned:
- The number of dimensions in an embedding model is important, but more isn’t always better. These days, almost every embedding model has around 1,000 dimensions, a significant increase from the previous average of 300.
- Choosing the right embedding model was challenging without testing our data. We settled on one of the top 5 models, and it’s been performing well so far. These models are like black boxes, meaning it’s impossible to know if a model is a good fit for your needs without trying it. Choosing any of the top models would likely serve you well. Don’t get too focused on the number of dimensions — start with whatever model you have access to.
- The size of the chunk had a greater impact on the quality of the results than the choice of the embedding model. No single chunk size consistently provides perfect answers. Run experiments to choose what’s more right for you.
- When one embedding size doesn’t suit all cases, it’s worth trying advanced strategies. However, this means more scenarios need to be tested thoroughly before deploying in production.
If you have made it this far, and want to know more, do continue to follow our journey.
Disclaimer: Things are changing faster than ever, so treat everything we say with caution. Just a few days after writing our previous post, OpenAI announced that they will soon allow GPT-4 for fine-tuning. Keep up-to-date before making decisions.
We are learning from:
1. https://arxiv.org/pdf/2307.03172.pdf
2. https://community.openai.com/t/the-length-of-the-embedding-contents/111471
