Generative AI 101: The right way to identify use cases is by understanding limits.
Written by Aravind Kondamudi and Purnesh Gali
One of the authors first discovered the transformative potential of a tool like ChatGPT in 2020, and it quickly became apparent that the world was never going to be the same. This revelation served as the genesis for Actalyst, where we identified Large Language Models (LLMs) as significant components of our future products. As we began integrating LLMs into our products in a variety of ways, we became increasingly surprised by their power and the speed of their evolution. This progress astounded us, despite our deep understanding of technology. We truly believe this technology will be transformative.
This revelation served as the genesis for Actalyst.
We believe in openness and community learning, but most discussions only skim the surface of the topic. So we decided to share our experiences and learnings from six months of experimentation with LLMs. The work we’re engaged in today is much more advanced than what we outline in these blog posts, so if you’re considering LLMs or already working with a more advanced scenario, we’d be happy to chat — feel free to reach out.
Limitations of Generative AI
There’s plenty of chatter about the use cases of Generative AI. We believe that understanding their strengths, particularly their limitations, is vital before pinpointing the use cases. After all, driving a car without knowing the rules and road conditions only increases the risk of accidents. We aim to lay out these rules and conditions to help you make informed decisions on how to use them.
Are there any scenarios where a bit of factual inaccuracy is acceptable?
The tricky part with Generative AI is ‘hallucination’, leading to potentially flawed decision-making when used in production. Are there any scenarios where a bit of factual inaccuracy is acceptable? Here’s where Text to Images (TTI) models differ from Language Learning Models (LLMs). When a TTI model ‘hallucinates’, it might create an unexpected image, which could be viewed as art. On the other hand, if an LLM ‘hallucinates’, it results in factually incorrect information that could lead to poor decision-making.

That’s a good start: if your use cases are purely artistic, there’s less cause for concern. Actually, these ‘hallucinations’ might turn out to be beneficial. (Our focus is Enterprise use cases of LLMs, so we will not delve into sound, animations, or other classes of models.)
Switching to LLMs, are there any scenarios where some factual inaccuracies are tolerable? We’re skeptical, but it’s possible some applications might be more forgiving. We often hear about summarization being a common application for LLMs, and while this may be true, it’s not the ideal starting point when thinking about use cases. That’s understanding just at the surface level.
There are other limits like high inference time, cost, etc., but they do not result in factual inaccuracies, so we will skip those for now.
Techniques to address limitations
To effectively identify use cases, we need to figure out how to minimize an LLM’s tendency to ‘hallucinate’. Although there’s no definitive ranking for which models hallucinate less, many agree that GPT-4 is considered the best model, followed by Claude, PaLM 2, etc., with various open-source models trailing behind. All LLMs are susceptible to ‘hallucinations’ or producing incorrect information.
There are several strategies to lessen an LLM’s ‘hallucinations’, which we broadly categorize into methods used ‘before the model is trained’, and those ‘used post-training’. It’s important to note that training a model to reduce hallucinations can be costly, so it’s advisable to do all you can to achieve desired results post-training. A post-training technique that’s become a buzzword is Prompt Engineering.
Fine-tuning large models can quickly become expensive
Prompt Engineering lets you smartly craft a prompt to get the output you want without any extra skills. Start by accessing state-of-the-art commercially available APIs like GPT-4 and give clever prompt engineering a shot for your specific use case. This could apply to tasks like summarization, code generation, sentiment analysis, chatbots, and more.
Prompt Engineering can be expensive. It is easy to start with, but an increase in prompt length results in a higher number of tokens needed for each API call, which in turn could lead to higher costs.
If Prompt Engineering doesn’t deliver the results you want, or it is expensive, the next step is to explore the ‘before the model is trained’ option. This is a nuanced topic, which we’ll delve into further in subsequent posts. For now, we’ll refer to this broadly as fine-tuning AI models.
we hope that, at the very least, you are beginning to understand the trade-offs and decisions involved.
There are various ways to fine-tune, but interestingly, very few top models offer this option. Take OpenAI, for instance. Their state-of-the-art model is GPT-4, but you can’t fine-tune it. You can, however, fine-tune their Davinci models, which are a few years old, and smaller in size, but nowhere to be found on the leaderboard. GPT-4 is considerably more advanced, so by opting to fine-tune Davinci over using GPT-4, you’re sacrificing a good deal of intelligence.
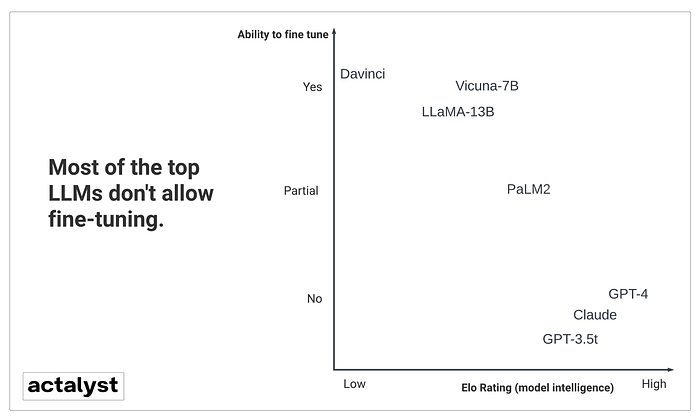
The above chart provides an overview of some models that permit fine-tuning and which don’t. Many of the state-of-the-art models do not allow fine-tuning. This means that you’ll be forgoing a significant amount of potential intelligence if you choose the fine-tuning route. Fine-tuning large models can quickly become expensive, requiring both skill and time. The choice of approach depends on the seriousness of the use case, which we will discuss later. However, we hope that, at the very least, you are beginning to understand the trade-offs and decisions involved.
Start here
Prompt Engineering is easy to start with, but it can become expensive. On the other hand, we have seen that choosing to fine-tune a model has its trade-offs. We’re afraid there are no straightforward answers, but we still believe that Prompt Engineering should be the starting point for all enterprise use cases.
If you’re solely using an API and coding in Python, we recommend trying out LangChain. Prompt engineering and LangChain can help reduce ‘hallucinations’ by allowing you to iterate until you get the desired result. While it may not be perfect, it should suffice for a variety of situations.
Prompt Engineering and LangChain can help
If Prompt Engineering isn’t yielding the results you want, and considering most of the top models do not allow fine-tuning, what options do you have? We’ll discuss various models and different fine-tuning techniques in our next post.
We could easily list suitable use cases and call it a day, but we want this explanation to be clear and detailed. In our next post, we’ll delve into the various ways you can fine-tune a model. Then, in our third post, we’ll apply all these insights to truly pinpoint suitable use cases. We’ll also share our experiences experimenting with different fine-tuning techniques and hyperparameter turning.
Disclaimer: The pace at which this field is advancing is breathtaking, so take everything we say with a pinch of salt. Double-check before applying it!
