GPT-4’s reasoning ability is pushing limits on what we thought is possible with LLMs.
Written by Purnesh Gali, and Srinivas Varma.
Creating good software is hard. It demands meticulous design and implementation across multiple layers, where even a minor issue in one layer can jeopardize the entire system’s success. At Actalyst, we believe that a well-designed data model is pivotal in maximizing the likelihood of success, much like the indispensable role a building’s foundation plays in ensuring its stability and durability.
You might be surprised to learn that in the world of analytics products, which primarily focus on processing data (Data Engineering) and deriving insights (Data Science), a significant amount of software engineering is woven into their development.
Take, for example, the seemingly straightforward task of enabling a business user to connect to multiple databases and extract valuable insights. A widespread requirement across various industries is to allow users to connect to multiple databases by inputting their connection details and credentials during their initial login. To enhance the user experience and streamline future logins, these details are stored securely, eliminating the need for re-entry.
Data model requirements
In our quest to develop an ideal schema, we aimed to address the following scenarios comprehensively:
From a database perspective:
- A single host can accommodate multiple databases, such as public, private, and others.
- Each database can house multiple schemas, such as sales, finance, and more.
- Diverse usernames enable access to different levels of data security; for instance, a ‘manager’ username might grant access to tables that an ‘analyst’ username cannot.
From a business user perspective:
- Business users can establish connections to multiple databases.
- A single business user can connect to the same database using different DB usernames, allowing them to assume various roles, such as ‘manager’ and ‘analyst’.
- Multiple business users can access the same database using identical usernames, exemplified by two users connecting to the same database as ‘analysts’.
Data model schema design
Building on our understanding of the outlined scenarios, we’ve crafted a data model that employs three core tables to ensure atomicity and maintain a streamlined structure:
- users: Captures essential business user details, such as user_id, email, name, and more.
- databases: Records database connection specifics, including hostname, port, and database name.
- schemas: Stores vital information about individual schemas.
To effortlessly accommodate the requirement of multiple schemas within databases, we’ve implemented an approach that focuses on the unique combination of host and database name. This strategy ensures seamless integration and organization of the schema data, paving the way for a robust and efficient data model.

As we delve deeper into the data model design, we encounter the challenge of determining where to store database credentials. Storing them in either the databases or schemas table would be inadequate, as a single database can accommodate multiple usernames, thereby violating the table’s atomicity. Furthermore, we need to address the scenario where multiple users log into multiple databases. To resolve these issues, we introduce a fourth table:
- user_database_connections: Manages database credentials and user mapping. This flexible table allows for multiple DB usernames and enables business users to connect to multiple databases seamlessly.

The challenge
So far, so good! We presented our requirements to GPT-4 and requested a data model design. GPT-4 delivered the precise data model outlined above.
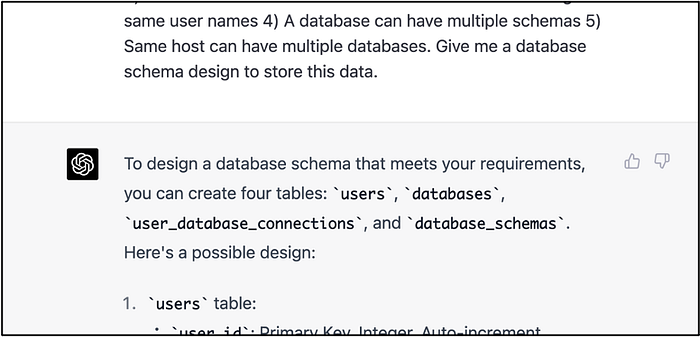
However, the initial data model designed by GPT-4 has a limitation: if a user_id connects to the same database_id using a different db_username, the schema_id they should have access to depends on the permissions associated with the db_username. The current data model doesn’t account for this
Consider the below example: how can we determine whether the db_username ‘manager’ has access to the ‘sales’ or ‘finance’ schema, or both?

GPT-4’s incredible reasoning ability
We were aware of this constraint before approaching GPT-4 and wanted to assess its reasoning capabilities. GPT-4 was unable to address this specific scenario with a simple prompt.
Continuing our exploration, we presented the scenario to both GPT-3.5 and GPT-4. GPT-3.5 failed to identify the blind spot in the schema design, even when explicitly prompted with the scenario. This resulted in a confidently incorrect solution from GPT-3.5.

When we posed the same scenario to GPT-4, its incredible reasoning capabilities shone through. GPT-4 not only acknowledged the gap in the schema design but also swiftly proposed a suitable solution. This experience showcased the remarkable advancement in GPT’s reasoning abilities within just a few months, highlighting the potential of AI-powered solutions for complex data model design challenges.
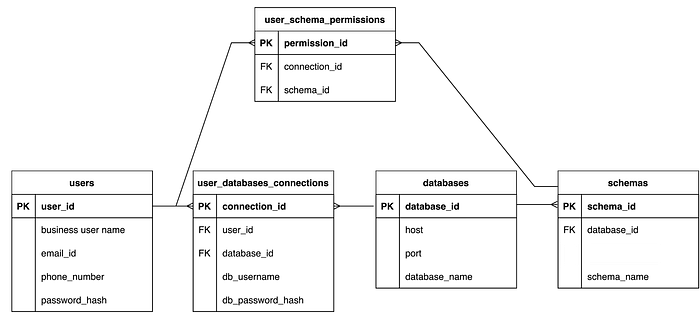
Designing a schema that can handle different users connecting to the same database using different usernames and different schema permissions was the main challenge in this use case.

Here’s the final schema that fulfills all the requirements.
Takeaways
We started developing a data model for a seemingly uncomplicated use case, focusing on the storage of database connection details by users. Although the use case was not overly complex, it required a level of reasoning that GPT-3.5 struggled to address, while GPT-4 excelled. Here are our key takeaways:
- GPT-4 exhibits impressive reasoning capabilities, even when tackling software-related challenges.
- To fully harness the power of GPT-4, you must possess a strong understanding of your craft. Providing specific instructions allows GPT-4 to deliver exceptional results.
- It’s important to remember that these models can exude confidence even when presenting incorrect solutions. Someone with limited data model design expertise might have confidently implemented GPT-4’s initial suggestion in a production environment.
- Finally, we can’t help but wonder about the potential impact of future GPT versions on data model design, a version that can better understand such nuances out of the box.
Note: Although this is an actual use case, we have not covered every aspect of it in this blog post. The scope of this is to showcase GPT-4’s reasoning abilities, and therefore, some details have been omitted to keep the post concise. We assume that the reader has a basic understanding of data model design.
